Diffuman4D enables high-fidelity free-viewpoint rendering of human performances from sparse-view videos.
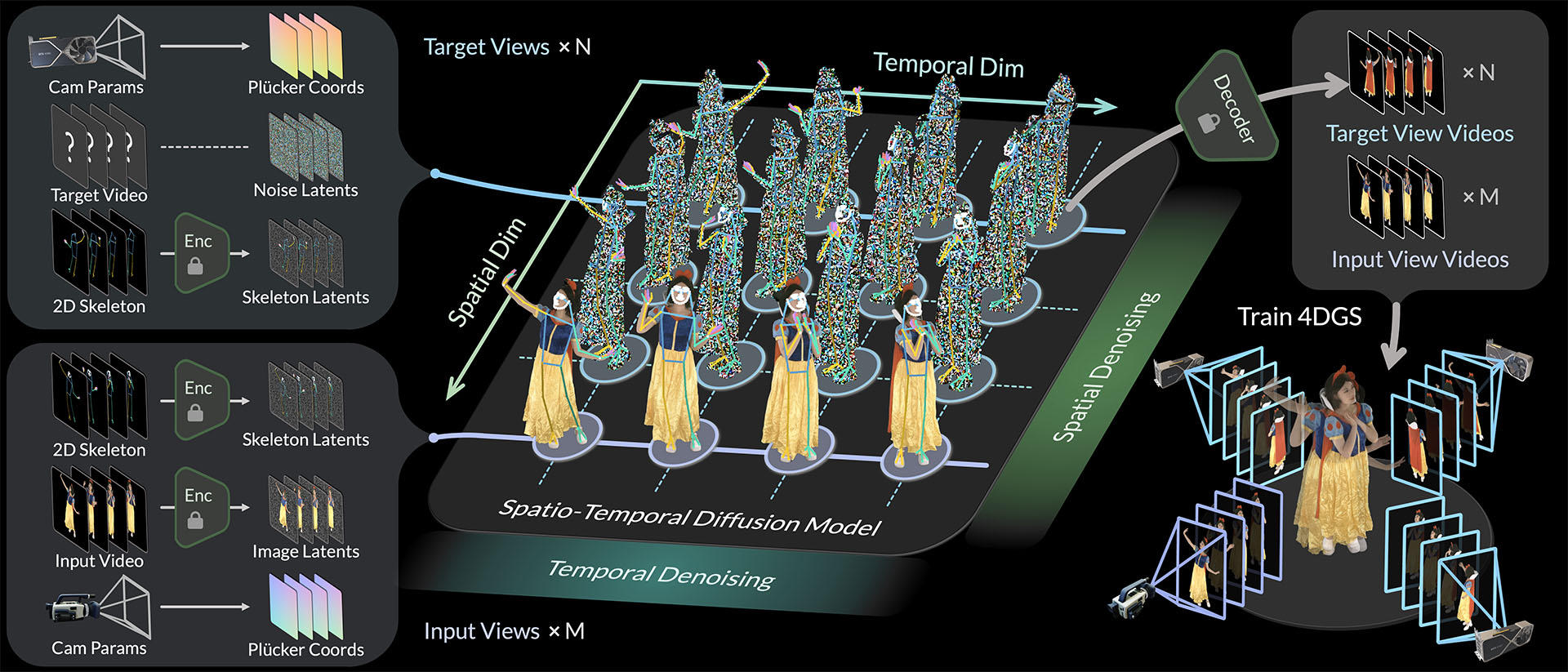
Given sparse-view videos, Diffuman4D (1) generates 4D-consistent multi-view videos conditioned on these inputs, and (2) reconstructs a high-fidelity 4DGS model of the human performance using both the input and the generated videos.
We introduce a spatio-temporal diffusion model to tackle the challenge of human novel view synthesis from sparse-view videos by:
To enable model training, we meticulously process the DNA-Rendering dataset by recalibrating camera parameters, optimizing image color correction matrices (CCMs), predicting foreground masks, and estimating human skeletons.
To promote future research in the field of human-centric 3D/4D generation, we have open-sourced our re-annotated labels for the DNA-Rendering dataset in dna_rendering_processed, which includes 1000+ human multi-view video sequences. Each sequence contains 48 cameras, 225 (or 150) frames, totaling 10 million images.


















We would like to thank Haotong Lin, Jiaming Sun, Yunzhi Yan, Zhiyuan Yu, and Zehong Shen for their insightful discussions. We appreciate the support from Yifan Wang, Yu Zhang, Siyu Zhang, Yinji Shentu, Dongli Tan, Peishan Yang, Shenghu Gong, and Yukang Ye in producing the self-captured demos. We also extend our gratitude to Ye Zhang for testing recent camera-control generative models and avatar reconstruction methods.
@inproceedings{jin2025diffuman4d,
title={Diffuman4D: 4D Consistent Human View Synthesis from Sparse-View Videos with Spatio-Temporal Diffusion Models},
author={Jin, Yudong and Peng, Sida and Wang, Xuan and Xie, Tao and Xu, Zhen and Yang, Yifan and Shen, Yujun and Bao, Hujun and Zhou, Xiaowei},
booktitle={International Conference on Computer Vision (ICCV)},
year={2025}
}